Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Dynatrace Community
- Dynatrace
- Ask
- Container platforms
- Detection of CPU throttling using Kubernetes application-only agent
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
13 Mar 2019
12:20 PM
- last edited on
13 Dec 2021
12:34 PM
by
![]() MaciejNeumann
MaciejNeumann
Does anyone here have any experience regarding Dynatrace's behavior when applications/services are impacted due to any involved services reaching their container-defined CPU limit while being monitored by way of a Kubernetes application-only agent?
By "behavior" I mean: Is Dynatrace able to pin-point to the problem root cause correctly (i.e. CPU usage has reached CPU limit and is being throttled) under these circumstances? Does the agent know about the CPU limits at all?
In our case we are currently running Dynatrace Managed 1.162 and using application-only agents for deep-monitoring of Java processes running as Docker images on a PaaS (OpenShift 3.9.60).
Unfortunately it's currently not (easily) possible for us to create a synthetic test scenario where CPU limits are reached in order to see what happens.
Any input is greatly appreciated.
Solved! Go to Solution.
Labels:
- Labels:
-
docker
-
kubernetes
-
openshift
Reply
4 REPLIES 4
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
14 Mar 2019 07:32 AM
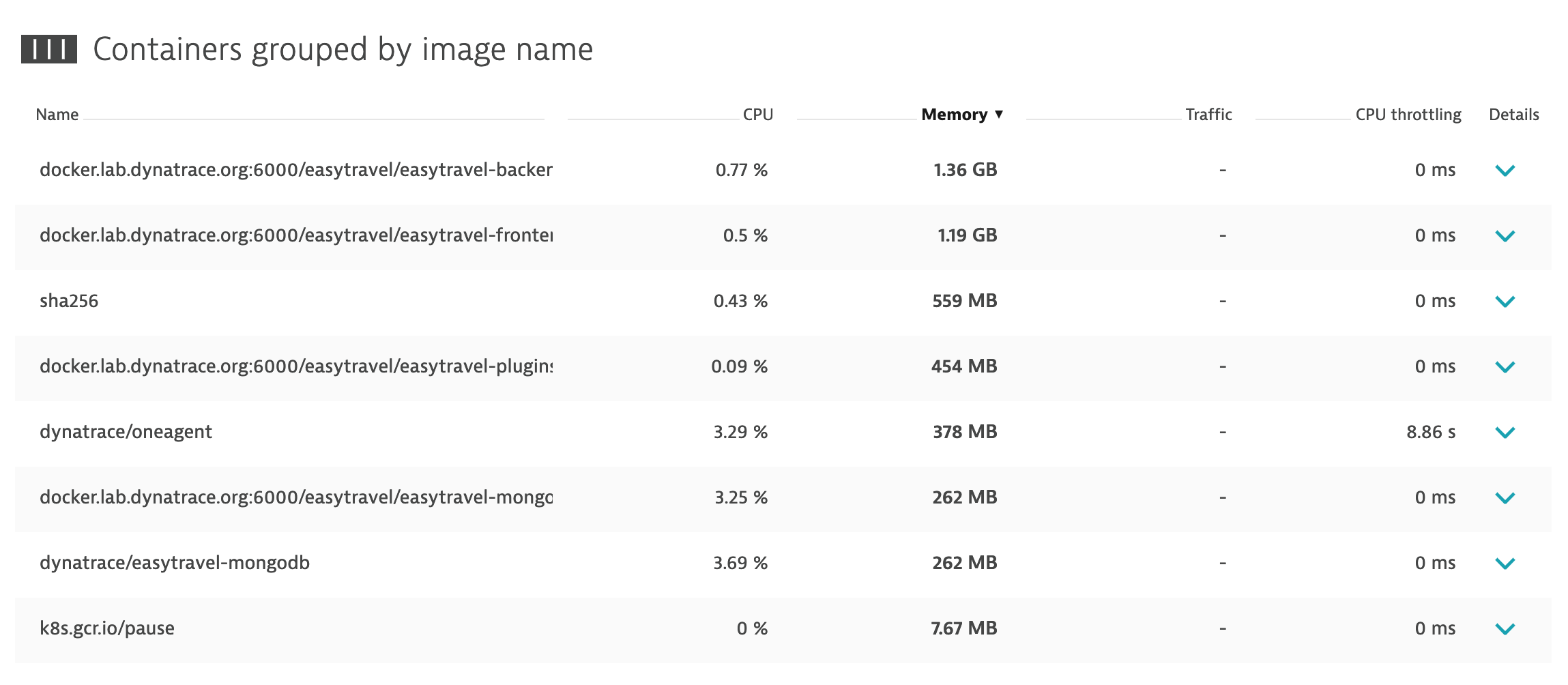
In general DT is collecting data about containers CPU like on screen I've pasted. So it should know what limit on CPU is set per container. We should have alert about that. But to be honest, I've never had before such issue on any environment I'm working with, so I can't tell you for sure 🙂
Sebastian
Regards, Sebastian
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
14 Mar 2019 08:57 AM
Thanks for the feedback.
Confirm you get the same info with application-only monitoring without a full-stack OneAgent installed on the underlying Docker/Kubernetes host?
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
18 Mar 2019 11:47 AM
You're right there are 2 options of deployment. I've never tried application only approach. As I understand it should monitor only processes and services, not all containers. So it may be issue here.
Sebastian
Regards, Sebastian
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
18 Mar 2019 10:45 AM
From the lack of feedback I conclude not many Dynatrace customers are using application-only monitoring or anticipating issues due to container CPU limits and throttling...
Anyway, in the meantime I found an interesting article about how to deal with application pauses which are due to Linux cgroups-induced CPU throttling in Java:
https://engineering.linkedin.com/blog/2016/11/appl...
As long as it's not clear if/how the application-only monitoring is capable of correlating application pauses with CPU throttling this may serve as a good reference.
Reply
