Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Looking to upgrade from Dynatrace Managed to SaaS?
See how
- Dynatrace Community
- Dynatrace Managed
- Dynatrace Managed Q&A
- Truncated transaction storage retention period
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
29 Dec 2017
06:36 AM
- last edited on
03 Mar 2023
06:33 PM
by
![]() Karolina_Linda
Karolina_Linda
Transaction storage retention period has been truncated for environment EPDyna due to insufficient disk quota. Please review Transaction storage settings on environment details page.
Our managed server doesn’t show of any space crunch. Can we know what can be done to fix this error. Please check the screenshot
![]()
Solved! Go to Solution.
Labels:
- Labels:
-
dynatrace managed
5 REPLIES 5
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
02 Jan 2018 08:36 PM
Might depend on your settings in Environments. Please verify how it is set up on your side - in case it's needed increase the limit. See a sample screenshot:
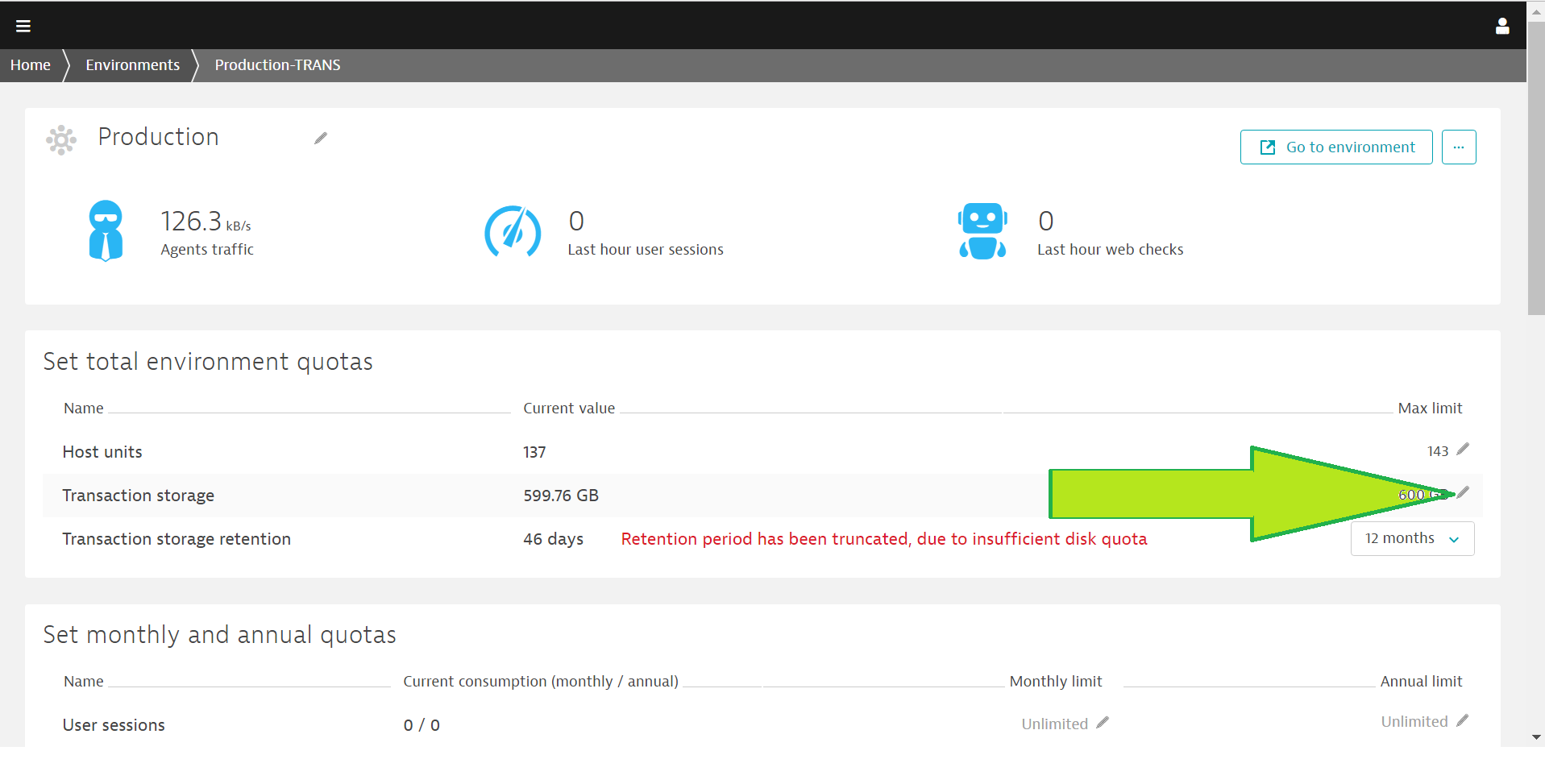
Senior Product Manager,
Dynatrace Managed expert
Dynatrace Managed expert
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
14 Jun 2018 06:32 PM
Hello, i've been facing the same problem in our cluster.
Which kind of data is in transaction storage?
What happen when this disk space get full?
-the newest data takes place of the oldest ones or the oldest data are "shrink" to allow new data storage?
Thanks in advance
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
15 Jun 2018 05:26 PM
Hi Victor,
Transaction storage is going to be your Purepath data. When the disk space is full it was start to truncate the data by reducing the length of time that it is holding your purepaths for. So the oldest purepaths will start to drop off to make room for the newer ones.
You can adjust this in the cluster management console. Another alternative is to add more storage for transactional data.
-Dallas
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
02 Nov 2018 02:41 PM
Hi,
We are having a very similar issue.
According to the hardware system requirements, the 'Small' Node Type (which is what we have) can have a maximum number of 250 hosts monitored. The Transaction Storage states that 500GB should give 10 days of code visibility. We have well under 250 hosts but still have 500GB of storage allocated.
However we are not getting the 10 days of code visibility. Our code level retention period fluctuates massively throughout our environments. We have around 12 environments configured, but most of them are only set to keep 3 days of data.
It seems that Dynatrace truncates the code level retention time period, rather than overwrite the existing code data and leave the code level time period in tact. So it seems eve nif we add more storage to the cluster, when it reached the maximum amount again, it would just truncate the time period again.
Hope all that makes sense. If anyone has any guidance or tips on this it would be most appreciated.
Thanks
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
02 Nov 2018 03:46 PM
Hi Andrew,
The 250 hosts and 500GB storage is the recommended amount for a small node. It is not an exact value. I think realistically if you had 100 hosts with enough traffic you could use more storage than 500GB code level storage.
The value that says it has 3 days of data is overwriting the tail end of the data as a rolling buffer. If you only allocate 500GB to your cluster it is telling you that the 500GB is only enough for 3 days worth of traffic at code level retention.
For example:If you added a terabyte of storage to that it should be able to hold more than 3 days worth of traffic if you have the "Max Limit" set high enough.
Let me know if this helps or brings up any more questions.
-Dallas
